AI制图以及FLUX模型的API调用与本地部署方法
AI制图思路以及FLUX模型的API调用与本地部署方法
随着AI Computer vision的发展已经诞生了多种类型的ai制图模型:Depth Estimation、Image Classification、Object Detection等等。本章博客主要写FLUX模型的Text-to-Image。
AI制图流程
我们知道一张图片其实是由很多个像素点构成的,从一句话到一张图片无非就是提取话中的意思,并转换成向量,通过大模型的计算,构成一个一个像素点,从而变成可以给人看的图片。
Model
FLUX.1-dev为官方满配模型,最低显存要求24G,生成图片质量高,但是会占用大量电脑算力。与之诞生的有FLUX.1-dev fp8,FLUX.1 schnell(蒸馏模型),FLUX.1 schnell fp8,Flux1-dev-bnb-nf4等优化版本供一般用户使用。不同的版本拥有不同的量化精度,我们可以对照以下表格来选择合适的模型。
| 格式 | 位数 | 说明 | 用途 |
|---|---|---|---|
| FP32 | 32 位浮点 | 默认的高精度格式 | 模型训练、推理 |
| FP16 | 16 位浮点 | 更低的精度,性能更高 | 推理加速、混合精度训练 |
| BF16 | 16 位浮点 | 宽指数范围,适合训练 | 深度学习训练优化 |
| FP8 | 8 位浮点 | 超低精度,节省显存 | 新一代硬件推理优化 |
| INT8 | 8 位整数 | 极低精度,硬件优化好 | 推理优化、TensorRT 支持 |
| INT4 | 4 位整数 | 更小精度,存储效率高 | 极端模型压缩、边缘部署 |
| NF4 | 4 位浮点 | 归一化的 4 位浮点格式 | 大模型权重量化 |
| GPTQ | 多位数支持 | 高效的权重量化方法 | LLaMA 等大模型优化 |
| AWQ | 低位权重量化 | 激活感知的权重量化方法 | 保证模型精度的量化 |
VAE
VAE全称Variational Autoencoder(变分自编码器),是一种常用于生成模型的深度学习结构。这种概率生成模型,能够学习数据的潜在分布并生成类似的数据。它由两部分组成:
Encoder(编码器)
将输入数据 xxx 映射到一个潜在空间,输出的是一个概率分布的参数(通常是均值 μ\muμ 和标准差 σ\sigmaσ)。
这个潜在空间的向量 zzz 是从这个概率分布中随机采样得到的。
Decoder(解码器)
- 将潜在向量 zzz 解码,尽可能地还原出原始数据 x′x’x′。
VAE 的总损失由两部分组成:
1 | |
- 重构损失(Reconstruction Loss):衡量生成的 x′x’x′ 与原始输入 xxx 之间的差异,通常使用 均方误差(MSE) 或 交叉熵。
- KL 散度(Kullback-Leibler Divergence):衡量编码器输出的分布 q(z∣x)q(z|x)q(z∣x) 与标准正态分布 p(z)p(z)p(z) 之间的差异,确保潜在空间分布合理,避免模型过拟合。
简单粗俗的说,VAE就是一个压缩包,它尽量提取这个图像的特征(也就是编码),那么我们的主模型FLUX就可以通过这些特征来进行计算,不需要每一个向量都要都要由FLUX计算,这样就提高了效率,也节省了算力。最后也可以由VAE来进行解压(解码),将图片预测扩散,从而变成我们想要的图片。
CLIP
全称为Contrastive Language–Image Pre-training,主要有以下四个特点:
文本引导:在ComfyUI这种模型中,CLIP 负责把 Prompt 翻译成“潜在空间向量”,引导模型朝着正确的方向生成。
图像识别:在反向提示词时,CLIP 也能识别哪些东西不该出现在图里。
风格对齐:如果你加了艺术风格的描述,CLIP 也能识别出来,并让图像风格尽量贴合。
Prompt Embedding:通过精细化的 Prompt 设计,CLIP 可以捕捉更微妙的图像特征,提升生成效果。
CLIP会将模型编码成嵌入组,用于引导扩散模型生成图像。
Sampler
Sampler(采样器)可以说是一个指挥官,它负责控制扩散模型在去噪过程中的步骤和方式。在AI生成图片时,会先在潜在空间里生成一张纯噪声图(这个纯噪声图是纯随机的,没有任何规律)。然后采样器通过集成噪波、引导器、k采样器、西格玛、Latent图像等参数进行除噪。
噪波:随机噪声,会随机生成种子,是生成过程的起始点。
引导器:提供附加条件信息,引导生成过程朝向特定目标。
k采样器:控制采样方式的策略,影响生成过程的质量和多样性。
西格玛:控制噪声强度的参数,影响图像中的噪声程度。
UNet:是一个神经网络结构,专门用于逐步去噪,在生成过程中接收潜在空间的数据,然后逐步去除噪声,直到最终生成图像。
Sampler:负责如何对 UNet 执行去噪操作,以及去噪的具体策略,比如去噪的步数、随机性、细节处理等。
噪点与向量的关系
- 噪点与潜在空间中的向量:
- 在生成图像的过程中,模型通常从一个噪声向量开始,而这个噪声向量会通过扩散模型的反向扩散过程(去噪)逐步转化为一个真实的图像。
- 向量代表了图像的潜在特征空间,而噪点则是这种潜在空间的一种随机扰动,表示一个完全无意义、随机的初始状态。
- 生成过程中的向量:
- 在前向扩散过程中,模型会将图像逐步添加噪声,最终得到一个完全的噪声图。这时图像的每个像素值是随机的,不能称为“向量”——它只是一个高维的随机噪声。
- 然后,在反向扩散过程中,这个噪声逐步被转化为一个更有意义的向量(图像的潜在空间表示),每一步的去噪都在让这个潜在向量向目标图像的特征空间靠近。
- 潜在向量的编码与解码:
- 在很多扩散模型(如Stable Diffusion)中,图像会被首先编码为潜在空间中的向量(通过类似 VAE的结构),然后才开始添加噪声或去噪。
- 这个潜在向量可以看作是图像的高维“表示”,而噪点则是它的随机扰动。在反向扩散过程中,模型会将噪点从这些潜在向量中去除,最终还原出一个清晰的图像。
ControlNet
ControlNet 是一种基于深度学习的 图像生成控制机制,特别是在扩散模型中,用来为图像生成过程提供更多的结构化控制。ControlNet 通过 额外的控制信号,使得生成的图像可以更好地遵循特定的约束条件或结构信息,从而更精确地生成用户所期望的图像。也就是说我们可以通过上传更多的图片来标准所要生成的图像。
LoRA
LoRA(Low-Rank Adaptation)是一种用于轻量级微调技术,旨在通过增加少量的参数来调整和微调模型,从而实现更高效的任务定制。
低秩矩阵分解:
- LoRA 的核心思想是低秩矩阵分解,它通过在神经网络的权重矩阵上引入一个低秩的适应层,来对模型进行微调。
- 通过这种方式,LoRA 只需要学习很少的额外参数,而不是直接修改原有的庞大模型权重。这样可以极大地降低微调大规模模型所需的计算资源和存储开销。
适应层的引入:
- 在 LoRA 中,通常会在模型的某些层(如 Transformer 层)中添加一个低秩矩阵,并通过这个矩阵来调节模型的行为。
- 这些低秩适应层是可训练的,并且它们的规模相对于原始模型的权重矩阵要小得多,这使得微调过程更加高效。
微调和预训练模型:
- LoRA 允许你在预训练的大型模型上进行微调,而不需要重新训练整个模型。你只需要调整少量的 LoRA 参数,这使得微调过程更加轻量且资源高效。
- 这对于资源有限的用户(如在 GPU 内存受限的情况下)尤其重要,因为 LoRA 允许你通过较少的计算和存储消耗,获得具有较好性能的定制化模型。
通过Lora我们可以将其他人训练的专一模型参数(比如皮肤光滑,二次元,朋克风等),让我们训练的图像更加偏向我们想要的部分。并且Lora不需要重建整个模型,因此我们只需要加入一个主模型,再加入几个副模型(Lora)我们就可以完成图片的生成。
Embedding
Embedding(嵌入)是一种将高维数据(如文本、图像、语音等)映射到低维向量空间的技术。这种向量表示可以保留原始数据的某些重要特征,并且便于在机器学习和深度学习模型中进行处理。目的是将复杂的数据(例如单词、句子或图像)转换为一个低维度的向量,使得模型能够理解并处理这些数据。在这个向量空间中,相似的输入会被映射到相似的向量,从而可以用数学方法计算它们之间的关系。比如词嵌入(Word Embedding):是将单词转换成一个固定长度的向量。例如,使用Word2Vec或GloVe这类算法,可以将每个单词映射为一个向量,这些向量在某种程度上反映了单词之间的语义关系。相似意思的词语(如 “king” 和 “queen”)的向量会在空间中非常接近。在图像中,可以用于图像检索或分类任务。
但是我们可以看到CLIP和Embedding都与向量生成有关,他们之间有什么区别呢?
| 特性 | Embedding | CLIP |
|---|---|---|
| 输入类型 | 单一类型的数据(如文本、图像等) | 同时处理文本和图像两种输入 |
| 输出 | 每个输入被映射为一个固定维度的向量 | 文本和图像被映射到相同的向量空间 |
| 用途 | 用于文本、图像等数据的向量表示、特征提取 | 用于跨模态(文本和图像)匹配、生成 |
| 模型架构 | 独立于单一模态的嵌入学习 | 通过对比学习同时训练文本和图像的嵌入 |
| 目标 | 提供单一数据类型的低维向量表示 | 实现图像和文本之间的相互理解和转换 |
我们可以看到Embedding作为一种通用的技术,它将单一类型的数据(如文本或图像)映射到低维向量空间,用于各种任务,如分类、检索等。
而CLIP则是一个多模态的模型,旨在将文本和图像映射到同一个向量空间,使得它能够处理跨模态任务,如图像描述生成、图像搜索、文本生成图像等。CLIP 的一个重要特性是,它能够理解并计算文本与图像之间的相似性,从而使得图像和文本在相同的向量空间中具有可比性。
API调用并使用Gradio可视化界面
api调用可以让庞大的计算任务在云端服务器进行,可以减少耗时,也可以使用更大数据量的模型。
进入huggingface我们可以看到官方api调用demo:
1 | |
provider是供应商;apikey需要自己注册,里面有关收费。
有了本地部署的demo,我们可以再加入ai生成中比较火的可视化库gradio。
1 | |
效果如下:
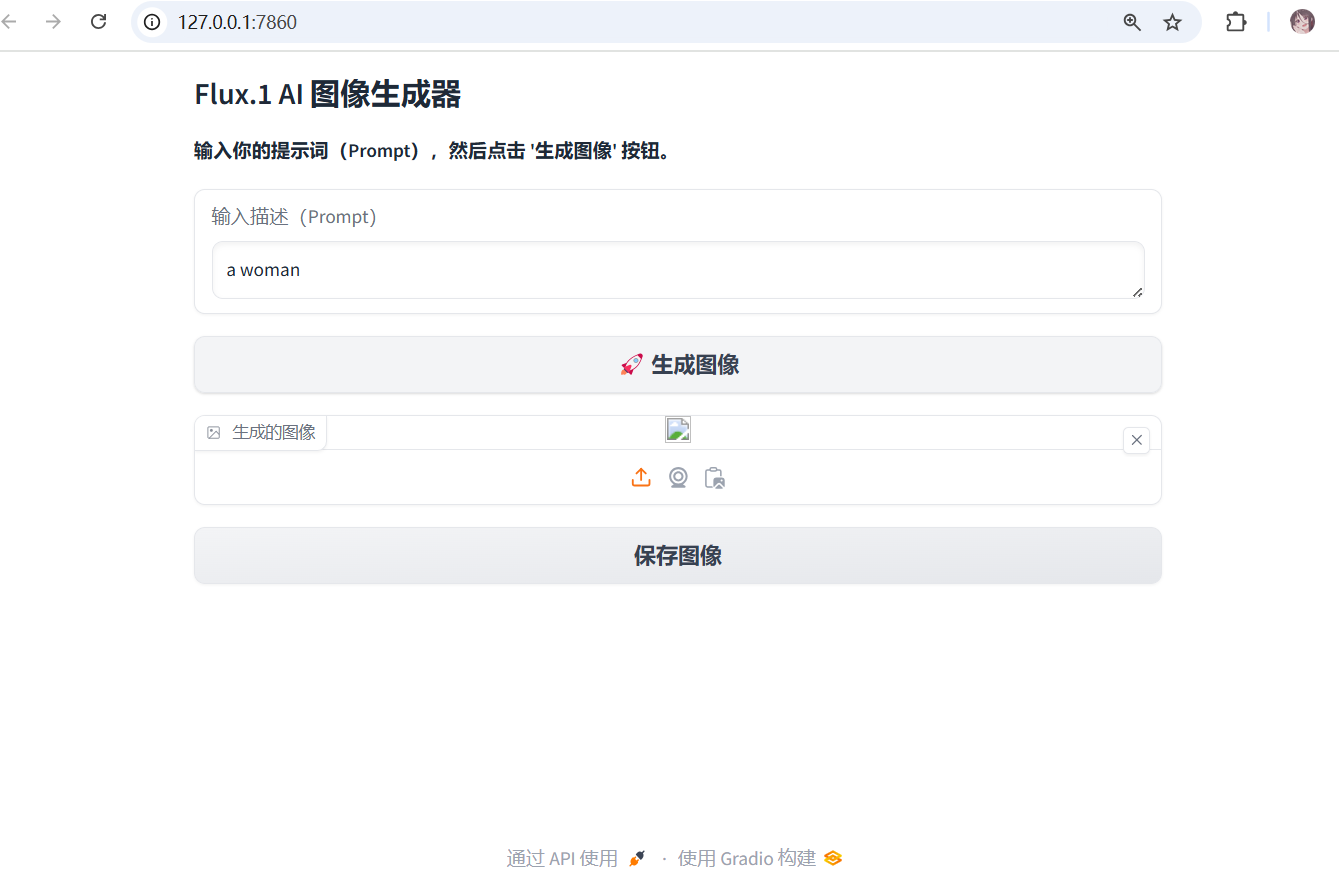
本地部署ComfyUI
ComfyUI是一个非常使用的ai制图工具,里面的工作流清楚明了。可以在github上的官方库地址下载。
使用模型的方法有很多种,我这里讲一种。下载模型均可在huggingface上找到开源的(FLUX.1dev需要24G,可以下载fp8模型(12G)或者schnell蒸馏模型,这个蒸馏模型预计8G显存可跑)。
然后下载CLIP模型( t5xxl_fp16.safetensors 或 t5xxl_fp8_e4m3fn.safetensors 还有 clip_l.safetensors)与VAE模型。
按照以下地址存放:
1 | |
然后点击run_nvidia_gpu.bat批处理文件就可以打开UI界面:
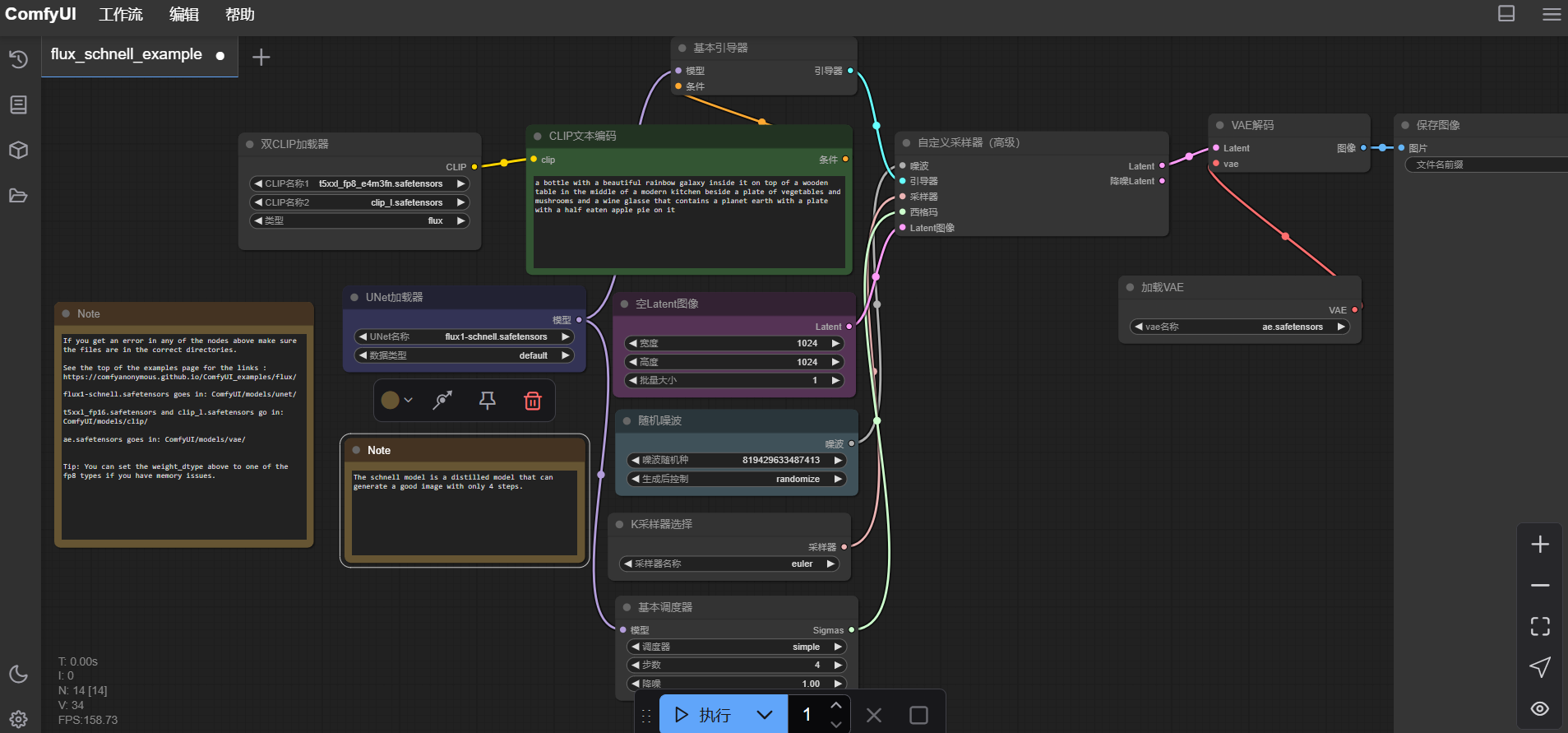
可以看到整个界面是十分明了的。