一键爬取个人绩点并计算平均绩点的脚本
不知各位有没有用过下图的教务管理系统:
虽然吧,你看着这个系统做的还不错,信息量非常足。但是其实我们学生并不关心什么课程代码,学年,学期这些信息,而且有个非常重要的点!它居然没有帮我们算平均绩点!这就导致每次学期结束,学校要统计综测的时候,都要用手指一个一个对着绩点按计算器,然后班长都要我们手动填表格,并让班长一个一个算出来分数,非常的让人蛋疼。

于是乎我就想弄一个脚本来帮我们直接刨析出各学期的绩点,并计算平均绩点、总绩点还有全年总平均绩点。
使用Fiddler进行代理实现网络抓包
思路
思路非常简单,通过Fiddler工具抓取每一次查询时接收的响应体,并找到响应体json文件中的信息,然后通过FiddlerScript(为JScript.NET语言)将响应体以txt文件形式保存到本地,然后通过python脚本解析txt文件使其可视化更强。
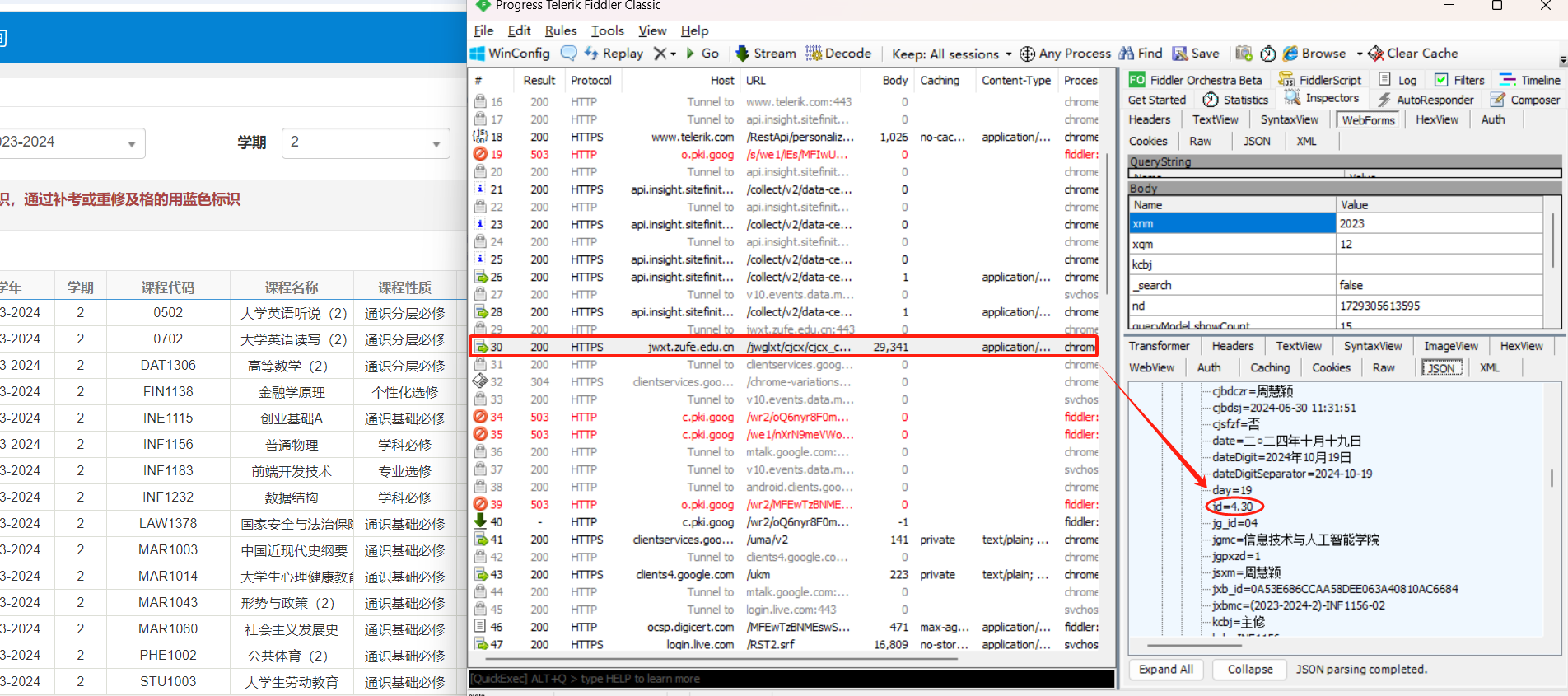
找到包及其绩点所在位置
点击”查询“按钮,我们在Fiddler中时刻关注此时跳出的包,经过查找,在url为:
1
| https://jwxt.zufe.edu.cn/jwglxt/cjcx/cjcx_cxXsgrcj.html?doType=query&gnmkdm=N305005
|
的包中有含有jd(绩点)信息,因此我们来捕捉这个包。
配置FiddlerScript将json文件下载到本地
打开FiddlerScript,找到OnBeforeResponse,然后输入下面JScript.NET代码:
1
2
3
4
| if (oSession.uriContains("https://jwxt.zufe.edu.cn/jwglxt/cjcx")) {
oSession.utilDecodeResponse();
var fileName = "C:\\Users\\yyn19\\Desktop\\college_score.txt";
oSession.SaveResponseBody(fileName);
|
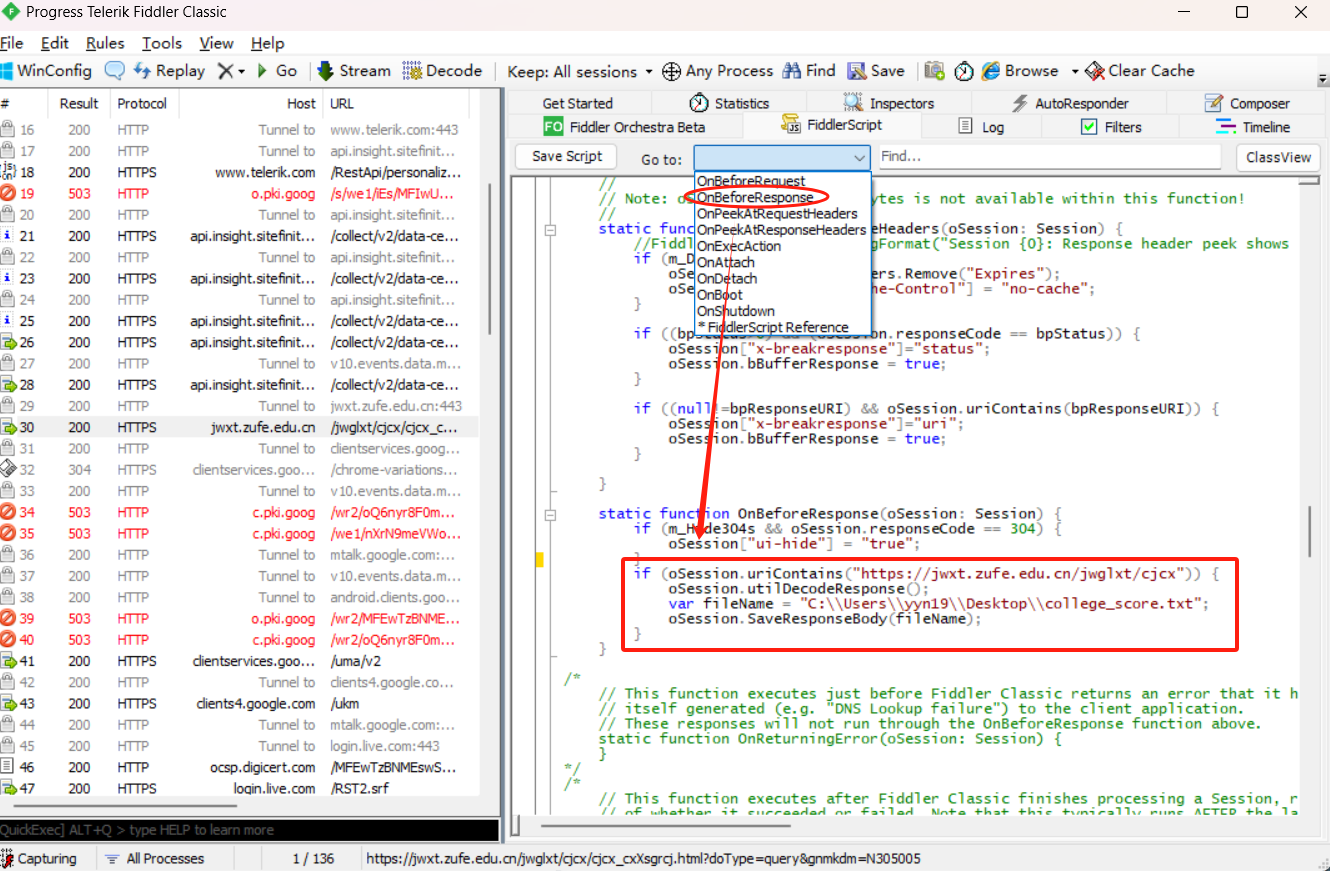
我将其下载到了桌面,当然你要下载到别处也可以。
用python脚本读取
单纯的用肉眼读十分的费力,这时候我们再借助一下python来解析json文件。在下面的path中填入你保存文件的位置,经过刨析,就可以得到各门成绩绩点和当前学期的平均绩点。
1
2
3
4
5
6
7
8
9
10
11
12
| path = "C:\\Users\\yyn19\\Desktop\\college_score.txt"
sum_score = 0
with open(path, 'r', encoding='utf-8') as file:
content = file.read()
data = json.loads(content)
for i in range(len(data['items'])):
print(data['items'][i]['jd'])
sum_score += float(data['items'][i]['jd'])
print(sum_score/float(len(data['items'])))
|
缺点
- 每一次运行脚本都需要手动点开各个学期的查询才能算出该学期的绩点平均值
- 需要Fiddler工具辅助
- 每一次都需要登录
于是我就想到用python自带的request方法来进行发送网络请求。
使用request库进行请求
思路
我们都知道一个http请求由以下几个部分组成:
- 请求行:包含请求方法(如GET、POST等)、URL地址和HTTP版本。例如,
GET /index.html HTTP/1.1。
- 请求头:包含了一系列键值对,用于传递附加信息,如客户端可接受的MIME类型、字符集、编码方式等。常见的请求头包括
Accept、Accept-Charset、Content-Length等。
- 请求体:包含要提交给服务器的数据。对于GET请求,请求体为空;对于POST请求,请求体包含提交的数据。
因此,我们只需要通过浏览器自带的抓包工具,找到url等一系列请求头和请求体(有时不需要)就可以发出http请求从而拿到数据。
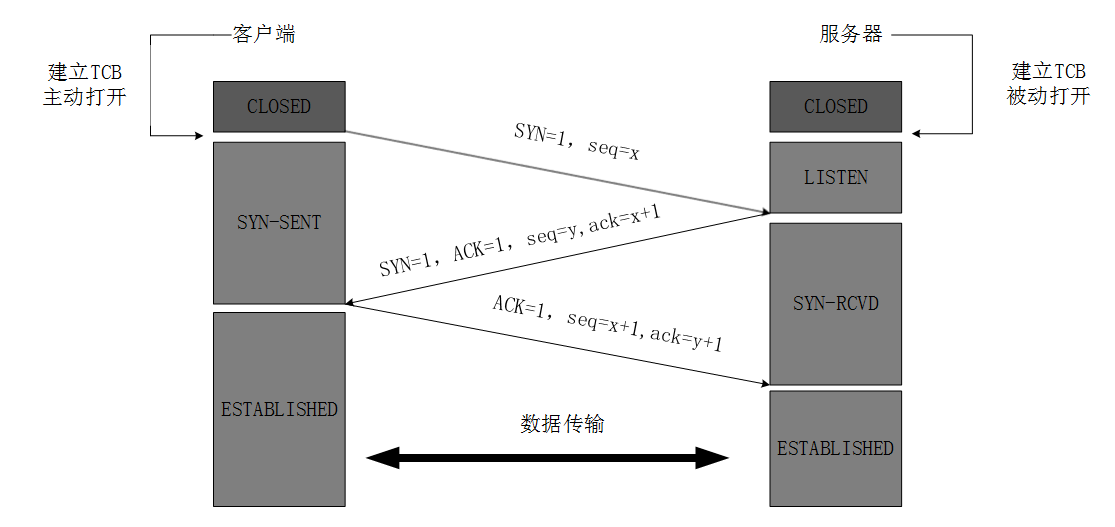
发送请求
首先我们先写入请求头:
1
2
3
4
5
| url = "https://jwxt.zufe.edu.cn/jwglxt/cjcx/cjcx_cxXsgrcj.html?doType=query&gnmkdm=N305005"
headers = {
"User-Agent": "你自己的User-Agent",
"Cookie": "你自己的cookie"
}
|
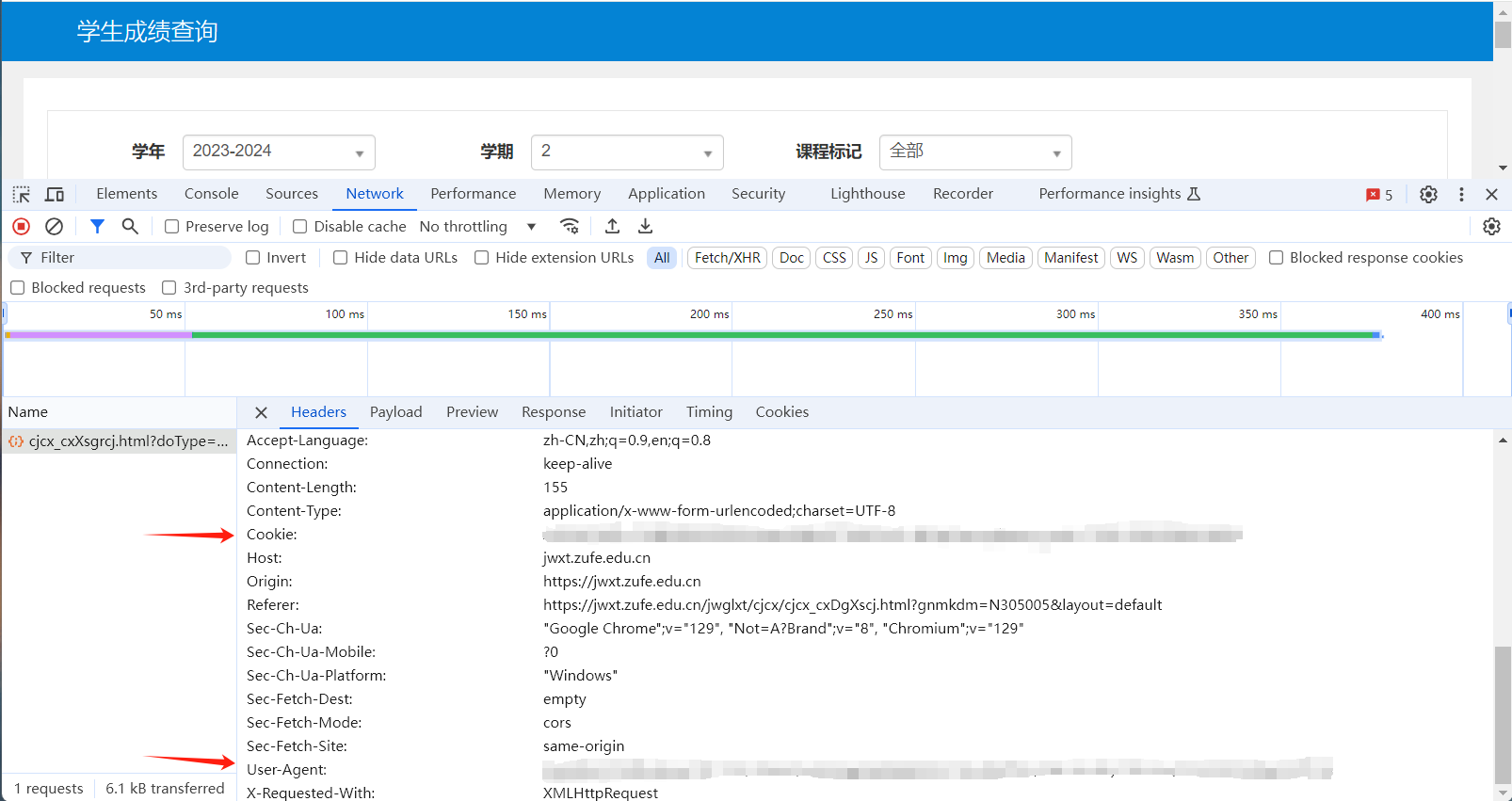
GET请求可以吗?
然后我们直接使用GET方法发送请求:
1
2
3
4
5
6
7
| import requests
url = "https://jwxt.zufe.edu.cn/jwglxt/cjcx/cjcx_cxXsgrcj.html?doType=query&gnmkdm=N305005"
headers = {
"User-Agent": "你自己的User-Agent",
"Cookie": "你自己的cookie"
}
response = requests.get(url,headers)
|
这时候我们发现:
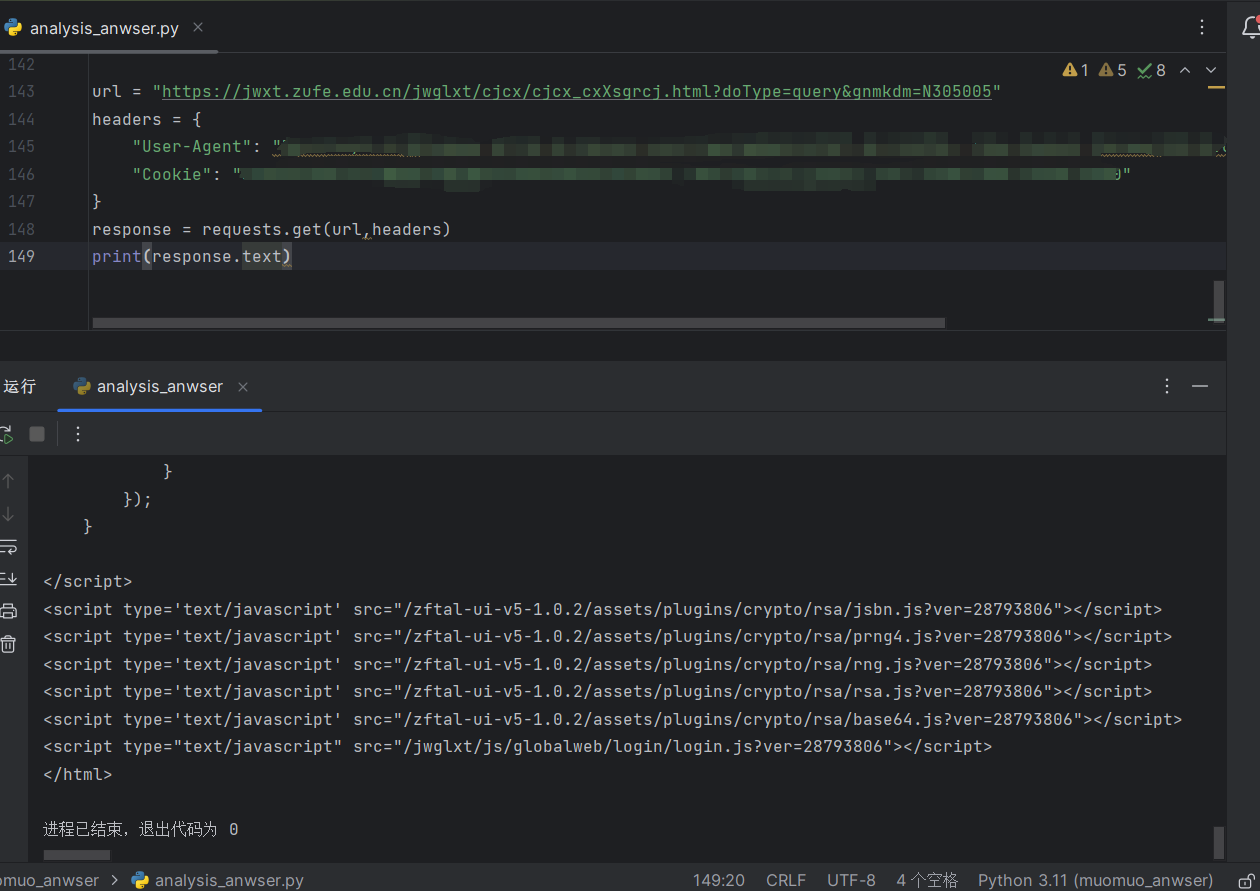
竟然得到的是这个网页的前端jquery文件,很显然这不是我们需要的答案。因此我们要选用POST请求。
选用POST请求
由前面我们知道POST请求包含了请求体,因此更能发送完善的请求来针对性的得到数据,这里我们就要再设置一个body来加入请求:
1
2
3
4
5
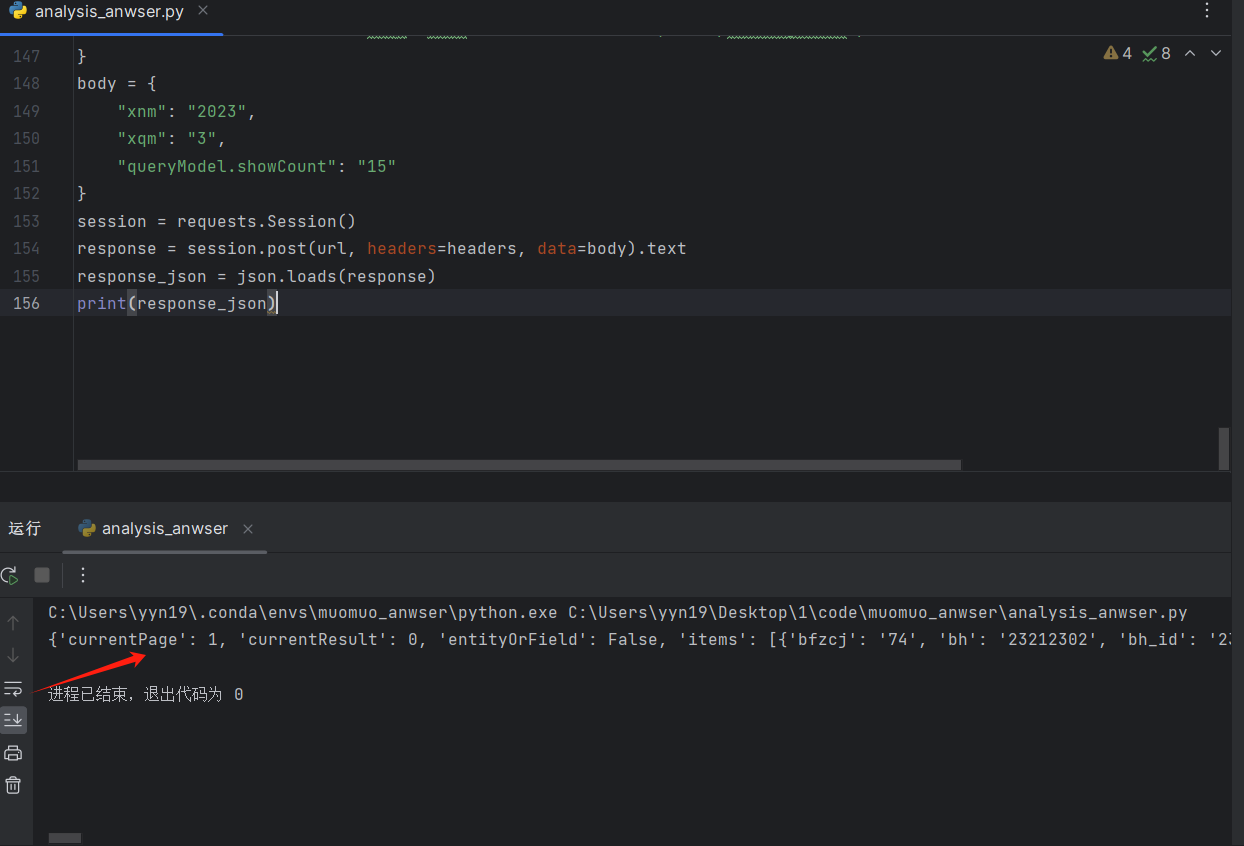
| body = {
"xnm": "2023",
"xqm": "3",
"queryModel.showCount": "15"
}
|
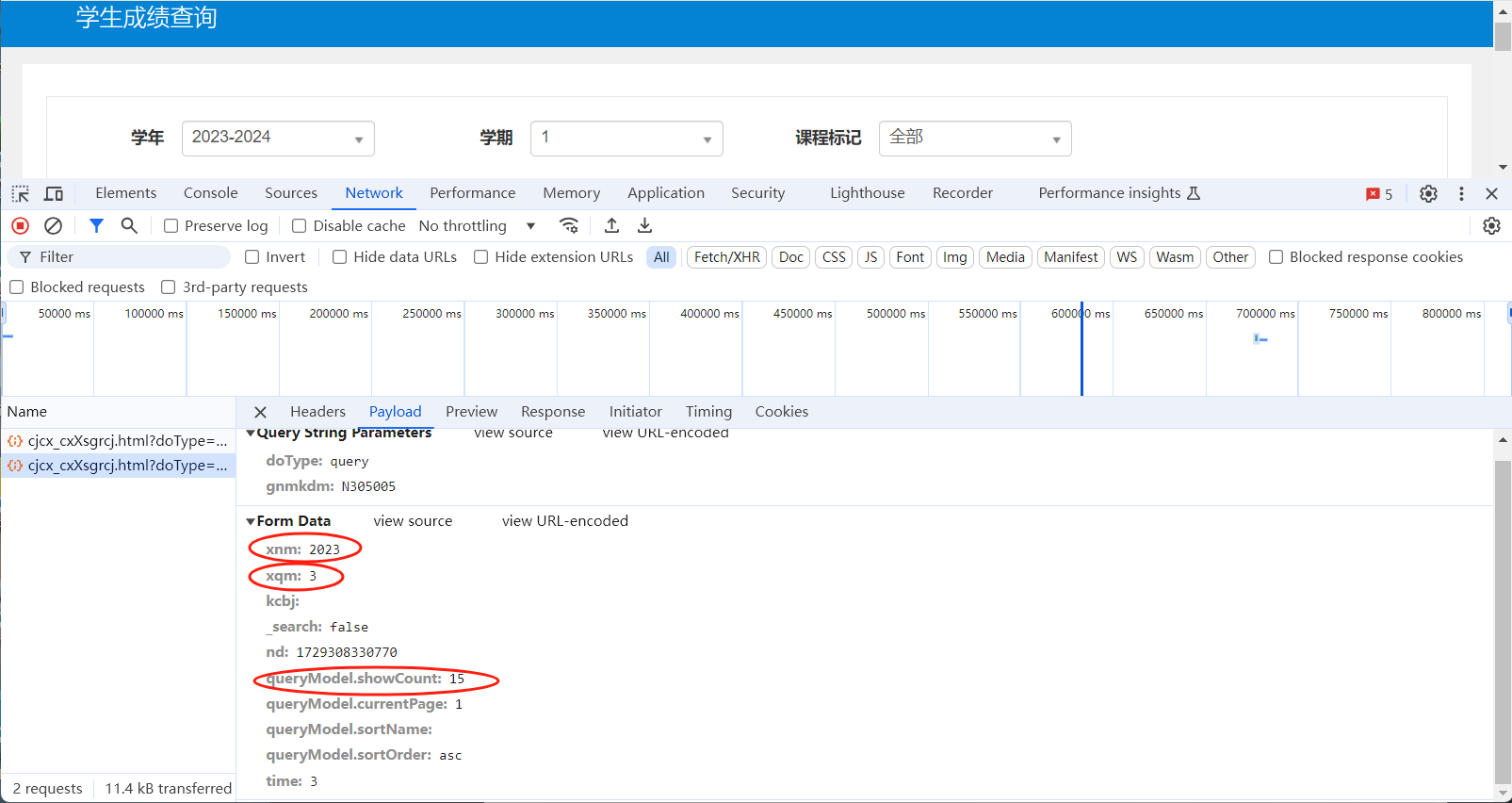
当然这里的值会随着学期和学年改变,之后完整代码用双重for循环来遍历。
然后调用request中的session,发出POST方法,并将str转化成json文件。
1
2
3
| session = requests.Session()
response = session.post(url, headers=headers, data=body).text
response_json = json.loads(response)
|
然后我们就得到了很长一串数据,然后不断的完善修饰数据即可。
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| import json
import requests
def send_to_server(url, headers, body):
session = requests.Session()
response = session.post(url, headers=headers, data=body).text
response_json = json.loads(response)
return response_json
def print_data(response, sum_score):
length = len(response['items'])
for t in range(length):
subject_score = str(round(float(response['items'][t]['jd']), 1))
subject = response['items'][t]['kcmc']
print(subject + ":" +subject_score)
sum_score += float(response['items'][t]['jd'])
avg_score = round(round(sum_score, 3) / float(len(response['items'])), 2)
avg_xq_score = str(round(round(sum_score, 3) / float(len(response['items'])), 2))
sum_xq_score = str(round(sum_score, 2))
print("该学期总绩点为" + sum_xq_score + ",平均绩点为" + avg_xq_score)
print("----------------------------")
return avg_score
class GetScore():
def __init__(self):
self.url = "https://jwxt.zufe.edu.cn/jwglxt/cjcx/cjcx_cxXsgrcj.html?doType=query&gnmkdm=N305005"
self.headers = {
"User-Agent": "你自己的User-Agent",
"Cookie": "你自己的cookie"
}
self.xq_num = ["3", "12", "16"]
self.xn_num = ["2023", "2024", "2025", "2026"]
self.body = {
"xnm": "2023",
"xqm": "3",
"queryModel.showCount": "15"
}
def analysis_xq(self, length, i, j):
if length == 0:
return 0
elif self.xq_num[j] == "3":
print(self.xn_num[i] + "第一学年")
elif self.xq_num[j] == "12":
print(self.xn_num[i] + "第二学年")
elif self.xq_num[j] == "16":
print(self.xn_num[i] + "第三学年")
def get_data(self):
all_avg_score = all_len = sum_score = 0
for i in range(len(self.xn_num)):
for j in range(len(self.xq_num)):
self.body["xnm"] = self.xn_num[i]
self.body["xqm"] = self.xq_num[j]
response = send_to_server(self.url, self.headers, self.body)
length = len(response['items'])
if self.analysis_xq(length, i, j) == 0:
break
else:
all_len += 1
all_avg_score += print_data(response, sum_score)
all_avg_score_str = str(round(all_avg_score / all_len, 2))
print("全年总平均绩点为:" + all_avg_score_str)
if __name__ == "__main__":
score = GetScore()
score.get_data()
|
效果展示
