爬虫 — 以爬取笔趣阁小说为例
1.发送请求
1
2
3
4
5
6
| import requests
url = "https://www.xzmncy.com/list/5418/2610707.html"
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0"
}
response = requests.get(url,headers)
|
这是requests请求,若返回response值为200,则表示请求成功
2.获取数据
1
| response = requests.get(url,headers).text
|
可以通过以上方法返回得到的html文件内容,而文件中有很多标签在里面,不能直接获取想要的信息,所以需要数据解析
3.解析数据
有以下几种途径:css、xpath、re正则表达 等等
让我们来看看分别用这三种方法怎么去解析到一个章节的标题
css
1
2
3
| import parsel
selector = parsel.Selector(response)
novel_title = selector.css(".bookname h1::text").get()
|
这种方法通过css选择器进行选择
xpath
1
2
3
| import parsel
selector = parsel.Selector(response)
novel_title = selector.xpath("//*[@class="bookname"]/h1/text()").get()
|
注意text后面的()
re
1
2
| import re
novel_title = re.findall("<h1>(.*?)</h1>",response)[0]
|
这里是因为h1在html文件中只有一个,故我直接导入。获取的数据是一个列表,所以我后面做了个且切片来直接获取字符串
*注意:以上方法各有利弊,选择合适的方式来解析数据
4.保存数据
1
2
| with open("file_name"+".txt",mode="w",encoding="utf-8") as f:
f.write(novel_context)
|
with open(download_path,mode=””,encoding=”utf-8”)中间的download_path可以写绝对路径
以上思路已经理清楚了,下面开始实践:
爬取一章
1
2
3
4
5
6
7
8
9
10
11
12
13
| import parsel
import requests
url = "https://www.xzmncy.com/list/5418/2610707.html"
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0"
}
response = requests.get(url,headers).text
selector = parsel.Selector(response)
novel_title = selector.css(".bookname h1::text").get()
novel_context_list = selector.css("#htmlContent p::text").getall()
novel_context = "\n".join(novel_context_list)
|
注意:join函数的使用:

1
2
3
4
5
6
| a=["1","2","8","9"]
print(" ".join(a))
print("\n".join(a))
b={"a":1,"b":2}
print(" ".join(a))
|
(注意seq不能是int整形)
爬取各章url
1
2
3
4
5
6
7
8
9
10
11
12
13
| import requests
import re
url = "https://www.xzmncy.com/list/18753/"
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0"
}
response = requests.get(url,headers).text
novel_name = re.findall("<h1>(.*?)</h1>",response)[0]
novel_info = re.findall('<dd><a href="(.*?)">(.*?)</a></dd>',response)
for novel_url_part,novel_title in novel_info:
novel_url = "https://www.xzmncy.com"+novel_url_part[0:24]
print(novel_url)
print(novel_title)
|
在小说的列表页面我们可以发现每个标签对应的章节url,此时我们获取的数据是这样的:
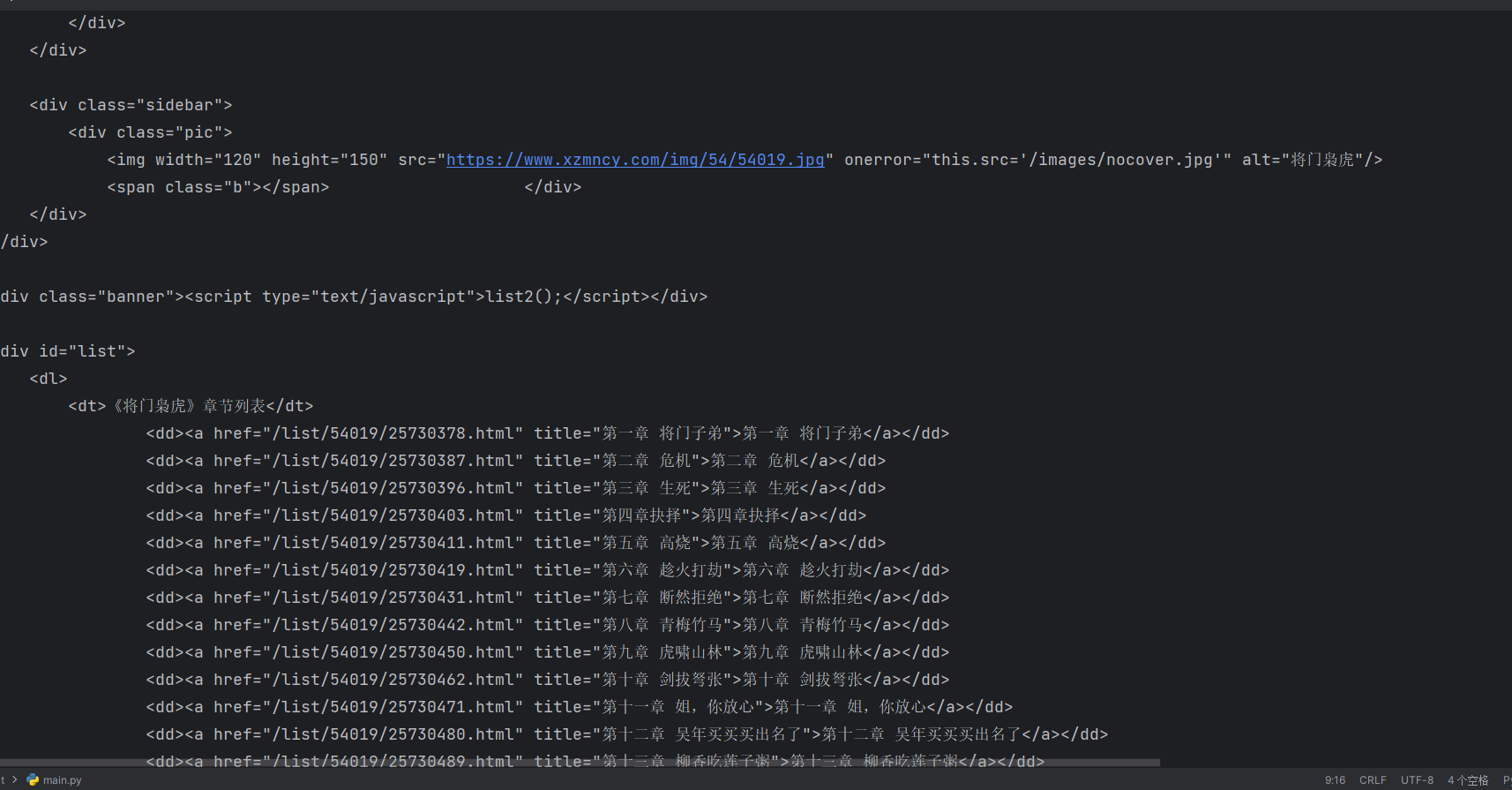
我们就可以用re来解析到各个章节的url和title
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import requests
import re
import parsel
url = "https://www.xzmncy.com/list/18753/"
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0"
}
response = requests.get(url,headers).text
novel_name = re.findall("<h1>(.*?)</h1>",response)[0]
novel_info = re.findall('<dd><a href="(.*?)">(.*?)</a></dd>',response)
for novel_url_part,novel_title in novel_info:
novel_url = "https://www.xzmncy.com"+novel_url_part[0:24]
novel_response = requests.get(novel_url, headers).text
selectors = parsel.Selector(novel_response)
novel_context_list = selectors.css("#htmlContent p::text").getall()
novel_context = "\n".join(novel_context_list)
print("正在保存"+novel_title)
novel_title = "*" + novel_title
with open(novel_name+".txt",mode="a") as f:
f.write(novel_title)
f.write("\n")
f.write(novel_context)
f.write("\n")
f.write("\n")
|
运行代码就可以看到当前的目录下出现一个txt文件,里面就是想要的小说啦~